
Невозможные вычисления на GPU
Секреты невозможных вычислений на GPU
Наша компания специализируется на оказании профессиональных услуг по обеспечению информационной безопасности - мелкого, среднего и крупного бизнеса. Мы предлагаем современные и надежные ИТ-решения, которые позволяют осуществлять управление доступом к сети Интернет и осуществлять защиту сети от внешних угроз. Портфель компетенций включает в себя внедрение, настройку и последующую поддержку следующих направлений: 1. Сетевые
Техническая
Задать вопрос специалисту -> Info@linkas.ru
|
Наша компания специализируется на оказании профессиональных услуг по обеспечению информационной безопасности - мелкого, среднего и крупного бизнеса. Мы предлагаем современные и надежные ИТ-решения, которые позволяют осуществлять управление доступом к сети Интернет и осуществлять защиту сети от внешних угроз. Портфель компетенций включает в себя внедрение, настройку и последующую поддержку следующих направлений: 1. Сетевые системы контроля доступа - межсетевые экраны Firewall и системы обнаружения/предотвращения вторжений (IPS/IDS):
2. Безопасность данных (Data Secreсy) - сетевые системы защиты данных, в том числе на уровне конечных устройств:
3. Контроль доступности данных:
Только сейчас - Бесплатная диагностика, расчёт сметы, техническая поддержка, гарантия - 2 месяца! Почта для вопросов и заявок - info@lincas.ru, sales@lincas.ru Горячая линия - Москва, Санкт-Петербург: +7 (499) 703-43-50, +7 (812) 309-84-39 |
В данной статье будет описан опыт по использованию вычислительного кластера из 480 GPU AMD RX 480 для решения математических задач высокой сложности.
Для примера было использовано доказательство теоремы из статьи профессора Чуднова А.М. “Циклические разложения множеств, разделяющие орграфы и циклические классы игр с гарантированным выигрышем“.
Суть задачи – в следующем: происходит поиск минимального числа участников одной коалиции в коалиционных играх Ним-типа. Данное число означает победу одной из сторон.

Статья будет также описывать суть и развитие CPU и GPU, их особенности и сравнение.
Немного о CPU
Самым первым процессором, который нашел широкое распространение у пользователей, был Intel 8086, созданный еще в далеком 1978 году. Как бы дико это ни звучало, его тактовая частота на тот момент составляла всего лишь 8 МГц. Сейчас, конечно, технический прогресс значительно продвинулся вперед, но в то время это было немыслимая высота.Через некоторое время появились процессоры, которые могли увеличить количество ядер от 2 до 8, и каждое ядро независимо от другого выполняло свой код. Это позволяло ускорить работу с данными в ощутимое количество раз.
И наконец – GPU
В одно время с развитием процессоров стали появляться и видеокарты. В самом начале все расчеты картинок выполнялись на CPU, но затем на некоторых видеокартах стали появляться сопроцессоры. В них был заложен набор команд, способных выполнять 3D вычисления. Как правило, это использовалось для развития компьютерных игр.
Вместе с этим, процесс разработки таких видеокарт сильно усложнился, поэтому в 1999 году компания nVidia выпустила свой процессор GeForce 256. Так и появился термин GPU – графический процессор. Он представлял собой нечто универсальное, был способен заниматься геометрическими расчетами, преобразованием координат, расстановкой точек освещения, а также работой с полигонами. Отличие такого процессора от обычных графических чипов заключалось в содержании стандартного набора команд. Они позволяли создать свой собственный алгоритм виртуализации.
Это позволило добавлять любые спецэффекты по своему воображению помимо тех, что уже были запрограммированы в видеокарту.
После появления GeForce 8000/9000 в GPU стали появляться потоковые процессоры. Их число могло быть от 16 до 128. Сейчас их называют унифицированными шейдерными блоками. К слову, на текущий момент количество таких блоков может быть увеличено до 4096 при тактовой частоте 1536 МГц. Но здесь, опять же, спасибо техническому прогрессу.
GPU: разбираем по полочкам
Архитектура графического процессора, в отличие от обычного, содержит в себе большее количество ядер, минимизированный набор команд, и направлены они в основном на векторные вычисления.Дополнительно на данном уровне решены все вопросы параллельной работы большого количества ядер и вместе с тем – доступа к памяти.
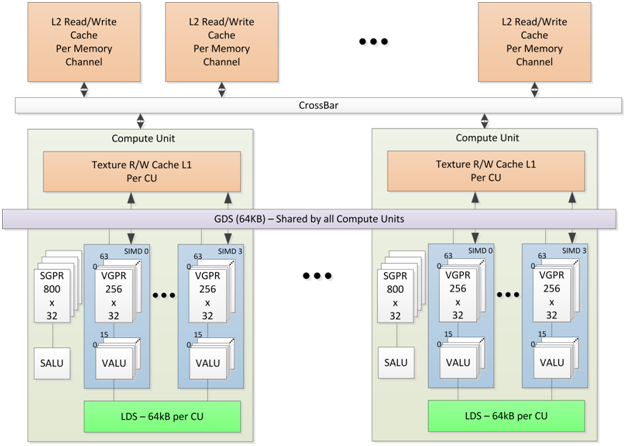
На текущий момент GPU могут содержать от двух до четырех шейдерных блоков (как было сказано ранее, максимум сейчас – 4096). Блоки в свою очередь объединяются в вычислительные юниты.
Стоит учесть, что при параллельных вычислениях существует некоторая проблема по одновременному доступу к памяти. Решается эта проблема таким образом: потоковые процессоры выполняют необходимые команды небольшими группами. В тот момент, когда одна группа занимается вычислениями, другая загружает регистры и т.п. Существует возможность объединить ядра в рабочие группы, которые будут обладать общей памятью и собственными механизмами синхронизации.
Есть еще одна особенность графических процессоров. Заключается она в том, что в них присутствуют векторные регистры и векторные АЛУ. Они могут выполнять операции одновременно для нескольких компонентов вектора. И данная особенность нашла свое широкое применение: как для 3D графики, так и для большинства физических вычислений.
Сравнение: CPU и GPU
Конечно, для полноценной работы оба типа устройств одинаково важны. Преимущество CPU в большом КЭШе памяти и высокой тактовой частоте. Но поскольку существует ряд задач, которые легко поддаются распараллеливанию, то эффективнее будет использовать именно GPU. Например, его польза очевидна при вычислении пикселей отрендеренного изображения. Происходит ряд одинаковых процедур для каждого пикселя, все необходимые данные об объектах хранятся в ОЗУ видеокарты. Каждый потоковый процессор может независимо от другого посчитать свою часть изображения. Это позволит повысить общую производительность при решении большинства задач подобного плана.Если обратиться к современным реалиям, то стоит обратить внимание на обучение нейронной сети. Именно GPU отлично подходят для решения данной задачи. Ведь процесс состоит из следующих этапов.
Достаточно большое количество одинаковых нейронов необходимо обучить (для этого меняются весовые коэффициенты каждого нейрона). Следующий шаг – через нейросеть пропускаются тестовые последовательности для обучения, и строится вектор ошибок.
Здесь потоковые процессоры GPU могут вести себя как нейроны. Тогда при вычислении уже не придется выстраивать решение последовательным образом, т.е. все вычисления будут происходить одновременно.
Таким образом, убедившись в преимуществе GPU, стоит посмотреть, какие еще применения можно для него найти.
GPU для программистов
GPU использует специальный язык и компилятор для выполнения различных вычислений. Для этого ему пригодятся несколько фреймворков, как например: penCL, CUDA, С++AMP, OpenACC.Тот же самый OpenCL вышел в свет в 2009 году под руководством компании Apple. Уже потом другие популярные корпорации (Intel, IBM, AMD, Google и nVidia)решили присоединиться к консорциуму Khronos Group, заявив о поддержке общего стандарта. После и теперь новые версии стандарта появляются с определенной периодичностью, привнося действительно серьезные улучшения.
Сейчас язык OpenCL C++ версии 2.2 соответствует стандарту C++14. Он поддерживает одновременное выполнение нескольких программ внутри одного устройства. Также язык способствует их взаимодействию посредством внутренних очередей и конвейеров, позволяя гибко управлять буферами и виртуальной памятью.
Ближе к реалиям
Ранее было сказано об эксперименте, который изучался с помощью GPU. Необходимо было найти минимальное число участников в коалиционной игре.
Используя математический подход, можно прийти к выводу, что все сводится к поиску опорной циклической последовательности. Можно представить последовательность в привычном виде списка 0 и 1, тогда проверка на опорность реализуется логическими побитовыми операциями.
Если же использовать подход программный, то данная последовательность будет представлять собой длинный регистр, пусть для примера будет 256 бит. И здесь самым надежным способом решения задачи будет использование всех вариантов, исключая невозможные по очевидным причинам.
Почему так важно решить данную задачу? Необходимо решить вопросы эффективной обработки сигналов. К ним могут относиться обнаружение, синхронизация, координатометрия, кодирование и т.д.
Камень преткновения заключатся в переборе действительного большого числа вариантов. То есть, если необходимо найти решение для n=25, это 25 бит, и т.д. Количество всех возможных комбинаций будет равно 2^25=33 554 432.
Но плюс в том, что подобную задачу можно легко распараллелить. И в этом как раз может помочь GPU кластер.
Программисты vs математики
Раньше данная задача решалась математиками на языке Visual Basic в Excel’е. Таким образом можно было получить первичные решения. К сожалению, возможности подобного языка не позволили продвинуться дальше. К примеру, для n=80 решение занимало полтора месяца.Итак, для первого этапа необходима была реализация алгоритма задачи на C и его запуск на CPU. Как приятное дополнение, обнаружились хорошие возможности по оптимизации при работе с битовыми последовательности.
За счет этого, удалось оптимизировать область поиска и исключить дублирование. Таким же образом появились хорошие результаты после анализа генерируемого компилятором ассемблерного кода и его оптимизации под особенности компилятора. Начало было положено, необходимая скорость при работе с вычислениями подобного рода достигнута.
Далее, удалось оптимизировать профилирование. Стало заметно, что в некоторых ветвях алгоритма ощутимо возрастала нагрузка на память, и как следствие – обнаружилось излишнее ветвление программы.
Здесь стоит также помнить, насколько важна аккуратность при написании кода. Поскольку верного решения задачи нет, то только данный фактор может гарантировать достоверность новых решений.
Наконец, подошел этап подготовки самой программы для решения задачи на GPU. Для этого потребовалось модифицировать код для работы в несколько потоков, а управляющая программа в свою очередь должна заниматься распределением задач между потоками. Так, скорость вычисления увеличилась в пять раз. Верные расчеты для n=80 получились всего лишь за 10 минут.
Использование OpenCL
Максимальную совместимость между различными платформами поможет обеспечить версия 1.2. Первичная отладка проводилась на обычном процессоре Intel, затем от того производителя на графическом, и потом – на AMD-шный.Выбор на данную версию пал еще и потому, что в ней поддерживаются целочисленные переменные размерностью 64 бита. AMD может поддерживать 128 бит, но компилируется в два 64-битных числа.
Для полной совмести и оптимизации производительности было принято решение представлять число 256 бит как группу 32-битных чисел. Логические побитовые операции над ними производятся на внутреннем АЛУ, причем довольно быстро.
Этапы и суть работы – в следующем. Программа на OpenCL содержит ядро-фукнци, которая в сою очередь является точкой входа программы. Далее данные, которые необходимо обработать, загружаются с обычного процессора в ОЗУ видеокарты, а затем – передаются в ядро в виде буферов (указателей на массив входных/выходных данных).
Далее ядро запускается в нескольких экземплярах. При этом каждое ядро должно знать свой идентификатор и использовать предназначенный ему кусок входных данных из общего буфера.
Еще одним преимуществом OpenCL наряду с этим можно указать возможность запуска множества потоков, при этом диспетчер задач разместит их на устройстве самостоятельно. Также, будет запущена очередь ожидания, которая поможет каждой задачи приступить к выполнению по мере возможности. Дополнительно каждый экземпляр ядра обладает своим пространством в выходном буфере. Там содержится ответ по окончанию работы.
Раз уже упомянули о диспетчере задач, стоит отметить его основную роль. Он занимается обеспечением параллельного выполнения некоторого количества экземпляров ядра. То есть, одна часть ядер загружает данные в регистры, другая в это же время работает с памятью либо выполняет какие-либо свои задачи. И суть диспетчера заключается в контроле над тем, чтобы все задачи, которые необходимо выполнить, стали на очередь выполнения здесь и сейчас.
Да, компилятор OpenCL может справляться с оптимизацией. Но многое все же зависит от разработчика.
Есть два направления оптимизации под графический процессор. Первое – ускорение выполнения кода, второе – возможность его распараллелить.
Второе направление во многом зависит от количества занимаемых scratch регистров, размера скомпилированного кода и количестве используемых векторных и скалярных регистров.
ComBox A-480
Итак, от Excel произошел переход к вычислительному кластеру. Он состоит из 480 видеокарт AMD.Необходимо учесть, что на всех этапах работы поиск решения проводился с самого начала и проводилось сравнению ответов новой версии с предыдущими. Это обеспечило уверенность, что все шаги по оптимизации и прочие доработки не вносят каких-либо ошибок.
Итак, запуск на данной вычислительной системе подтвердил домыслы о скорости решений. Поиск последовательностей для n, которые больше ста, занимал действительно около часа. На данном кластере новые решения находились за считанные минуты, при этом на центральном процессоре это могло занять несколько часов.
Спустя два часа работы были получены все решения до n=127. Их проверка показала, что все полученные ответы могут быть достоверными, а также что они соответствуют теоремам, указанным в используемой для сравнения статье.
Развитие
Рост производительности можно отследить следующим образом:- полтора месяца до n=80 в Excel;
- час до n=80 на Core i5 с оптимизированной программой на С++;
- 10 минут до n=80 на Core i5 с использованием многопоточности;
- 10 минут до n=100 на одном GPU AMD RX 480;
- 120 минут до n=127 на ComBox A-480.
Можно обозначить некоторые области их применения:
- задачи автоматического управления транспортными средствами и дронами;
- расчеты аэродинамических и гидродинамических характеристик;
- распознавание речи и визуальных образов;
- обучение нейронных сетей;
- задачи астрономии и космонавтики;
- статистический и корреляционный анализ данных;
- фолдинг белок-белковых соединений;
- ранняя диагностика заболеваний с применением ИИ.